Hive , Hive on Tez
Hive 는 Hadoop 기반이다.
대규모 데이터 솔루션중 하나라고 생각하면 되겠다.
주요 역할은 다음과 같다.
ETL : 데이터 추출, 변환, 로드를 수행한다. HDFS 에 저장할수 있다.
데이터 쿼리 및 분석 : Hive는 HQL을 사용해서 대규모 대이터를 쿼리하고 분석한다.
저장 및 관리 : 다양한 처리 도구와 연동 가능하다. Hbase, Spark, Impala 등과 연동되며, RDBMS 와도 연동가능
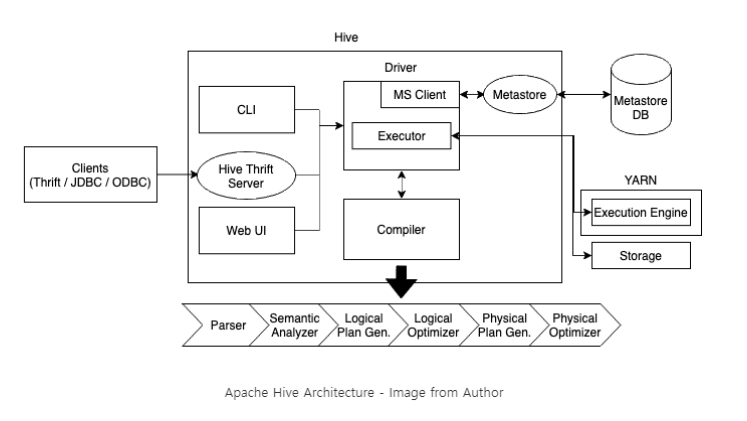
그렇다면 Hive on Tez 는?
Hive on Tez는 Hive를 데이터 처리엔진 중 하나인 Apache Tez 위에 구현한 것이다.
Hadoop MapReduce 의 단점을 보완하기 위해 개발된 데이터 처리 엔진중 하나이며, 빠른 데이터 처리 성능을 제공한다.
HQL을 Apache Tez 위에서 실행하여, 효율적이고 빠른 데이터 처리를 가능하게한다.
Hive on Tez 는 Hive on MapReduce 와 비교해서 성능이더 뛰어나고 메모리사용량도 적다.

두 엔진을 비교한 architecture 인데 거의 비슷하다. 역시 mapper 와 Reducer 는 근본인 것인가..
다음 설계를 보면 그모든것을 컨트롤하는것이 YARN 이다 . 이제 빼놓을수없는 YARN을 알아보자.

Hadoop 에서 사용되는 Yarn 은 도대체 뭘까?
Spark 을 사용하던, Hive를 사용하던 Yarn 은 필수적으로 사용되지만 그 기능에대해서는 분산처리를 도와준다는 추상적 의미만 알고있을뿐이어서 이번에 알아보았다.
(사실 resource error 가 발생해서 알아봤다)

위의 Architecture 를 보면 대표적으로 Client, Resource Manager, Node Manager 가 있다.
여기서 Client 는 Resource를 요청하는 프로그램 즉 Hive나 Spark 이라고 보면 되겠다.
Yarn 을 실제로 구성하고 있는요소는 3가지인데
Resource Manager
클러스터의 전체 자원을 관리. application 을 실행하기위해 노드매니저와 컨테이너를 할당
Node Manager
클러스터 개별노드에서 실행되는 로컬 서비스이며, 할당된 컨테이너를 실행하고 컨테이너에서 실행할 자원을 할당받는다
Application Master
app은 app master 를 통해 자원을 요청하게된다.
여기까지가 yarn 의 기본개념이다.
나에게 발생했던 오류는 app master 가 요청한 memory는 2GB 인데 Resource manager 에서 할당할수있는 최대 memory가 1.7GB로 제한돼 있어서 발생한 문제였다.
최대 max memory 할당을 2.5GB로 조절하고 시스템을 제기동해서 해결..?
되지 않았다… Node manager 의 memory 최대 할당도 변경해줘야 했다.